Today, we (Thrum) are introducing our first Proof-of-Concept of NOMT, the Nearly-Optimal Merkle Trie Database. NOMT is inspired by this blog post by Preston Evans of Sovereign Labs, and we are targeting Sovereign-SDK as the first user. Sovereign Labs has funded the implementation work with a grant.
NOMT is a permissively-licensed, single-state, merklized key-value database targeted at modern SSDs, optimized for fast read access, fast witnessing, and fast updating. NOMT supports efficient merkle multi-proofs of reads and updates. It is intended to be embedded into blockchain node software and is unopinionated on data format. Our vision for NOMT is for it to become the primary state database driver for performant blockchain nodes everywhere.
Against a database of 2^27 (~134M) accounts and a single-threaded execution engine, NOMT can read, modify, commit, prove, and write an update of 50,000 accounts in 1151 milliseconds, with a peak SSD read of 2.42G/s and a peak SSD write of 822MB/s. The actual trie commit, prove, and write operation takes only 431ms, so the main bottleneck is reading state during execution, not merklization. See the last section for more information on our benchmarking methodology, as well as comparisons to other databases.
Code is available at https://github.com/thrumdev/nomt and is written in Rust.
This is only our first proof-of-concept, after beginning the project 2 months ago. We intend to optimize this much further over the next 6 months.
Why Optimize This?
We optimize state access and merklization because they are the number one real bottleneck in scaling blockchains, currently.
Block execution and comitting is disk I/O bound: reading and writing information to the disk. Whether it’s for a node proposing a block, validating it for consensus, or simply receiving and executing it, transactions may read from unpredictable accounts or contract data and this will need to be fetched.
Reading from RAM takes a few hundred nanoseconds. Reading from an SSD can take a few hundred microseconds. Frequently-accessed data can be cached, but not all the data.
Disk I/O overheads dwarf the overhead of actually executing transactions, by comparison. These transactions need state data: account balances, smart contract state, smart contract code, or their analogues in non-smart-contract based systems. While the most frequently used bits of state are usually cached in a node’s RAM, large state databases with billions of entries are simply too large to fit into RAM. Execution pauses while waiting on this state data.
Disk I/O is compounded by the need for state merklization: organizing the blockchain’s state into a merkle tree, which allows light clients (including bridges and zero-knowledge circuits) to efficiently inspect the value of any particular piece of state based only on a tiny root commitment or verify that a series of updates to one state leads to a new root commitment. Not all blockchain systems use a merkle trie to store state. Bitcoin and Solana are two notable examples of systems which don’t. In our opinion, merklizing the state of large smart contract systems is critical for enabling global, permissionless access to blockchain systems.
NOMT in particular is solving for disk I/O and computation as it relates to state merklization, while being friendly to the critical path of block authorship.
The Solutions
NOMT aims to prove that blockchains don’t need to sacrifice state verifiability for scaling.
NOMT has been built according to the following design goals:
- Read from flat key-value storage during block execution. Most modern blockchain architectures are bottlenecked on the speed of block execution, and in particular, block building. Traversing a merkle trie data structure during this stage will lead to unnecessary latency and reduce scaling potential. Keeping a flat store of all key-value pairs makes block execution fast.
- Pre-fetch merkle trie data aggressively. Modern SSDs are particularly good at parallel fetches. We optimize for having as many parallel, in-flight requests for merkle trie data as possible at any given time, even going as far as pre-fetching trie data based on hints from the user’s reads and writes before block execution has concluded.
- Update the trie and generate witnesses while waiting on the SSD. Reading from an SSD necessarily incurs some latency. We keep the CPU busy whenever we are waiting on data, so updates are “free” and wedged between SSD read waits.
- Optimize merkle trie storage for SSD page size. This is the main innovation from Preston’s post. SSDs keep data in “pages” of 4KB, and reading a single byte from a page requires loading the whole page. It’s better to pack your data into whole pages and minimize the number of pages which need to be read from the SSD. See Preston’s post for some more information on this.
We currently have built on top of RocksDB as a storage backend for trie data. RocksDB is an embedded key-value store from Facebook, which is widely used in blockchain node implementations. In our next milestones, we plan to implement a customized database backend to further improve the performance of NOMT.
The theoretical maximum performance of NOMT will be achieved when we can max out I/O Operations Per Second (IOPS) on a consumer SSD. Despite our initially strong benchmarks, there is still quite a lot of room for improvement.
Benchmarking
We performed a cursory benchmark of NOMT, sov-db (from the Sovereign SDK), and sp-trie (from Substrate).
The benchmarks were performed on a machine with these specs:
- AMD Ryzen 7950X 16-Core Processor
- 64GB RAM
- Corsair MP600 Pro LPX 4TB SSD (1M IOPS)
- Linux 6.1.0-17
- Ext4 Filesystem
Our backends:
NOMT: f97d3c418 (recent master branch)
sp-trie: 32.0.0
sov-db: 2cc0656df (https://github.com/sovereign-labs/sovereign-sdk)
We created one database of 2^27 accounts for each of our test targets. Each account is a 256-bit key with a 64-bit “balance” value.
The benchmark performed 1,000,000 “transfer” operations. In each operation two deterministically pseudo-random accounts are selected, and the balance of one account is read and incremented while the other is read and decremented. In 25% of the runs, the incremented account is fresh.
In two key ways, this is a “worst-case” benchmark: most blockchain usage follows a power-law distribution, where something like 80% of the state reads are on 20% of the state. Fully random accesses are the absolute worst-case for a blockchain, but are needed to serve the long tail of global usage rather than the fat tail of power usage. Furthermore, generating merkle proofs including all read data adds additional overhead which could be skipped on a normal validating full node.
All benchmarks used the same random seed, and operations were split into 40 batches each of 25,000 operations - a “workload”. The OS page cache was cleared before each run. We recorded peak I/O usage with iotop at a sampling frequency of 10Hz to collect our I/O stats data.
The backends each committed the changes to the database and generated a merkle proof necessary to prove all changes.
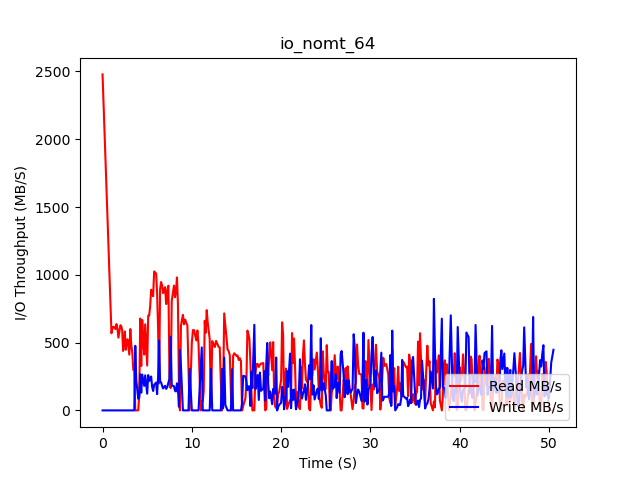
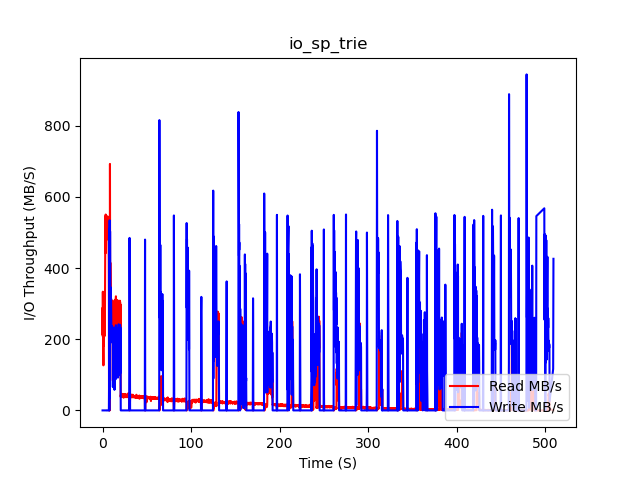
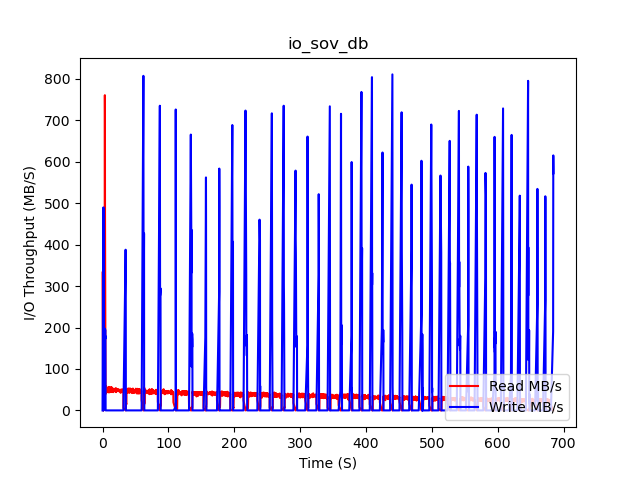
We can observe that in all benchmark runs, the amount of read throughput falls dramatically after a short peak early on, and then continues to slowly fall. This is because the Linux page cache is beginning to cache most of the commonly-read pages.
Without further ado, here are our results:
NOMT (64 reader threads)
22:17:28
metrics
page requests 37753709
page disk fetch mean 232 us
nomt
mean workload: 1151 ms
mean read: 13159 ns
mean commit_and_prove: 431 ms
22:18:18
note: NOMT has been instrumented with some additional metrics and has additional data.
sp-trie (Substrate)
22:39:28
sp-trie
mean workload: 12530 ms
mean read: 212 us
mean commit_and_prove: 874 ms
22:47:59
sov-db (Sovereign SDK)
22:48:28
sov-db
mean workload: 17075 ms
mean read: 17754 ns
mean commit_and_prove: 16144 ms
22:59:52
sov-db is based off of the Jellyfish Merkle Trie implementation from Diem/Aptos and inherits quite a lot of their code, with some modifications by Penumbra and Sovereign.
Interpreting the Results
NOMT is the clear winner, but still has quite a lot of head room. Note that the 64 reader threads
are mostly idle and are a result of using synchronous disk I/O APIs - using more threads enables us
to saturate the SSD’s I/O queue, but the same effect could be achieved with fewer threads and
an async I/O backend like io_uring or io_submit.
sp-trie has an extremely low random read speed, because it traverses the merkle trie on each read. This is exactly why we have chosen to keep a flat store for key-value pairs, so as not to block execution on trie traversals.
sov-db has a flat store like NOMT, but has much more data due to being an archival database and keeps the trie nodes in the same RocksDB “column” as the trie nodes. This leads to slower reads.
NOMT’s peak read of 2415MiBs is equal to the value given with a fio run on the same machine and corresponds to 618k IOPS:
> fio --name=fiotest --numjobs=16 --filename=test3 --size=35Gb --rw=randread --bs=4Kb
--direct=1 --ioengine=io_uring --iodepth=16 --startdelay=5 --group_reporting --runtime=30
fio-3.33
Jobs: 16 (f=16): [r(16)][100.0%][r=2428MiB/s][r=621k IOPS][eta 00m:00s]
fiotest: (groupid=0, jobs=16): err= 0: pid=3382952: Sun May 19 14:35:18 2024
read: IOPS=618k, BW=2415MiB/s (2533MB/s)(70.8GiB/30002msec)
slat (nsec): min=751, max=201767, avg=1267.80, stdev=378.84
clat (usec): min=14, max=9398, avg=826.52, stdev=456.98
lat (usec): min=15, max=9399, avg=827.79, stdev=456.99
Notably, all databases we benchmarked have a large read spike at the beginning. This is likely an artifact of RocksDB.
NOMT’s typical disk read throughput is around 300MiB/s, corresponding to only ~75k IOPS. It is also still quite short of the total 1M IOPS advertised by the manufacturer. Our goal is to utilize all these IOPS with a custom disk backend.
In any case, we are reaching a point where state merklization is not the main bottleneck, and state read performance is - meaning that nodes using NOMT could reach throughtput levels in the same neighborhood as Solana without compromising on performance, state merklization, or greatly increasing hardware requirements.
Optimizing state read (as opposed to merkle trie read) performance is somewhat beyond the scope of NOMT. Using multiple threads rather than a single thread would likely yield better performance to parallelize state reads. In a blockchain setting, serializable execution and optimistic concurrency control may be used to achieve this.
Watch this space as we max out SSD throughput with NOMT.